WooCommerce-Shop-Indexierung — was blockieren und was bei Google behalten

Ein Shop hat 2.000 Produkte, aber die Google Search Console erkennt 80.000 Adressen. In den Ergebnissen erscheinen Sortierseiten, leere Tags, der Warenkorb und zufällige Filterkombinationen. Gleichzeitig gelangt ein Teil der wichtigen Kategorien und Produkte gar nicht in den Index.
Das ist ein typisches Problem von WooCommerce-Shops. Ein einzelnes Produkt kann über eine Kategorie, die Suche, einen Filter, einen Kampagnenparameter, eine Variante und mehrere Sortierarten erreichbar sein. Für den Kunden sind das verschiedene Wege, dasselbe Angebot zu durchstöbern. Für Google können das einzelne URLs sein, die besucht und bewertet werden müssen.
Es geht nicht darum, möglichst viele Seiten zu blockieren. Zu aggressive Einstellungen können wichtige Kategorien aus Google entfernen, dem Robot den Weg zu Produkten abschneiden oder dazu führen, dass die Suchmaschine das noindex-Tag nie zu sehen bekommt.
In diesem Ratgeber zeigen wir, welche WooCommerce-Seiten indexiert werden sollten, welche man üblicherweise aus Google ausschließen sollte und wann man noindex, einen Canonical, robots.txt, eine 301-Weiterleitung oder einen 404-Fehler einsetzt.
Kurz gesagt
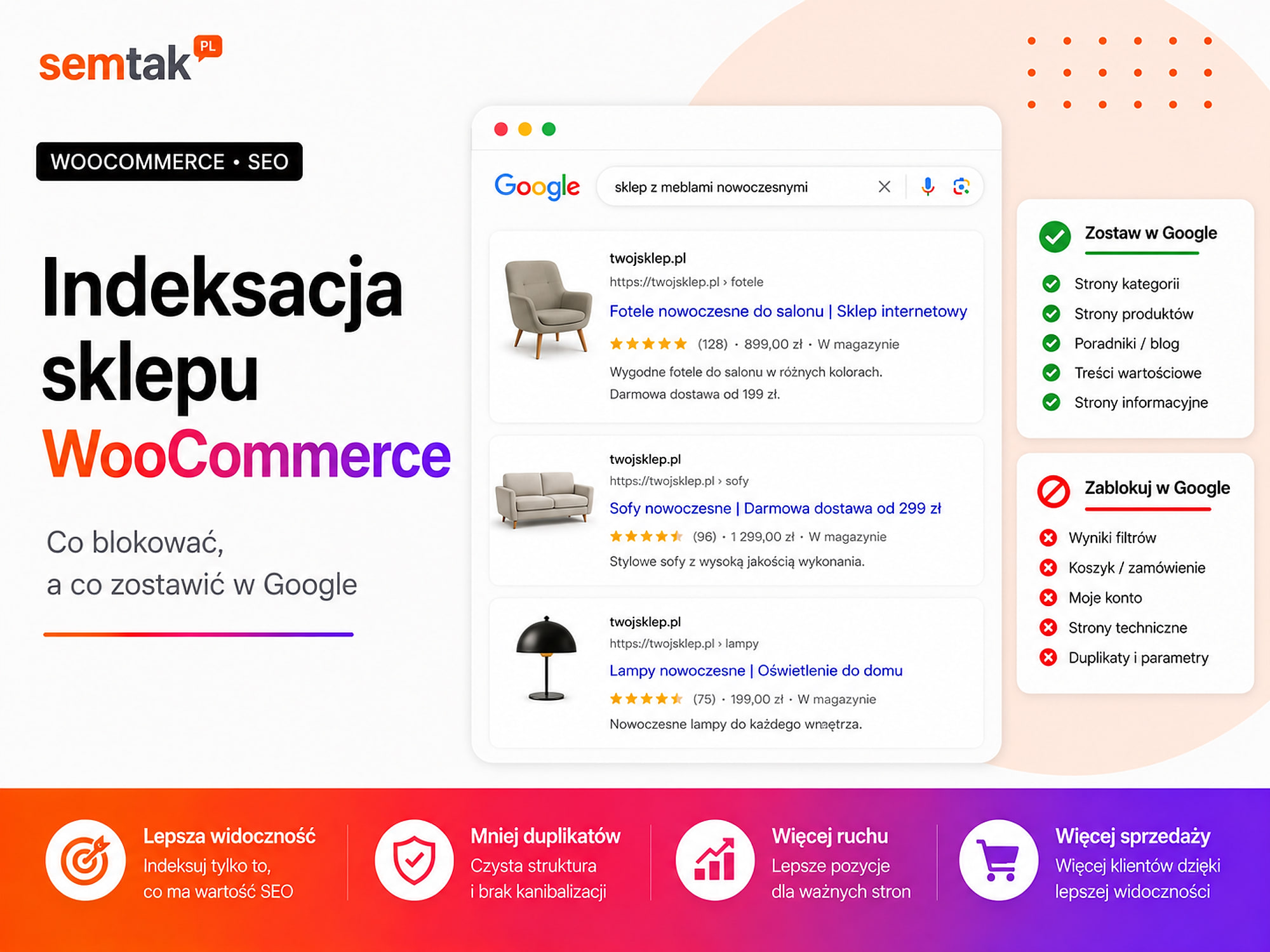
Im Google-Index sollten vor allem bleiben: die Startseite, wichtige Kategorien und Unterkategorien, verfügbare oder zurückkehrende Produkte, ausgewählte Markenseiten, eigens erstellte Landingpages, die echte Suchanfragen beantworten, sowie Ratgeber und andere wertvolle Inhalte.
Außerhalb des Index sollten üblicherweise bleiben: der Warenkorb, der Checkout, das Kundenkonto, die Bestellbestätigung, interne Suchergebnisse, Sortieradressen, die meisten Filterkombinationen, dünne Tags und automatische Archive sowie private und technische Nutzerseiten.
Blockieren Sie nicht alles in der robots.txt. Dieses Werkzeug schränkt das Besuchen von Adressen durch Robots ein, dient aber nicht dazu, Seiten aus den Ergebnissen zu entfernen. Wenn Google noindex oder einen Canonical sehen soll, muss es die Seite betreten können.
TL;DR
- Indexierung bedeutet, dass Google eine Seite in seiner Datenbank speichern und in den Ergebnissen anzeigen kann.
- Kategorien, wertvolle Produkte, vorbereitete Markenseiten und Ratgeber sollten für die Indexierung verfügbar sein.
- Der Warenkorb, der Checkout, das Kundenkonto, die interne Suche und zufällige Filter sollten üblicherweise
noindexhaben. robots.txtsteuert das Crawling,noindexdie Indexierung, der Canonical weist auf die bevorzugte Version, und eine 301 verschiebt eine Adresse dauerhaft.- Kombinieren Sie nicht automatisch mehrere Mechanismen gleichzeitig. Klären Sie zuerst, ob eine Seite ein Duplikat ist, entfernt wurde oder einfach nicht bei Google erscheinen soll.
- Blockieren Sie die Paginierung nicht ohne Analyse. Google braucht gewöhnliche Links zu den nächsten Seiten, um tiefer liegende Produkte zu erreichen.
- Ein vorübergehend nicht verfügbares Produkt sollte üblicherweise unter derselben Adresse bleiben und den Statuscode 200 zurückgeben.
- Die XML-Sitemap sollte nur Adressen enthalten, die indexiert werden sollen und einen 200-Code zurückgeben.
- Der Befehl
site:liefert nur eine schnelle Vorschau. Treffen Sie genauere Entscheidungen auf Basis der Search Console, eines Crawls und der Serverlogs.
Worin unterscheidet sich Crawling von Indexierung?
Google muss eine Seite zuerst finden und besuchen, bevor es entscheiden kann, ob es sie in den Index aufnimmt. Der Prozess lässt sich auf vier Stufen vereinfachen:
- Entdeckung der Adresse — Google findet die URL in einem Link, der Sitemap oder auf einer anderen Seite.
- Crawl — der Robot lädt den Code der Seite herunter.
- Rendering und Analyse — Google liest den Inhalt, die Links, den Canonical, die strukturierten Daten und die Robots-Einstellungen.
- Indexierung — die Suchmaschine entscheidet, ob die Seite in den Index aufgenommen wird und unter welcher Adresse.
Eine Seite kann Google also bekannt, aber noch nicht besucht sein, besucht, aber nicht indexiert werden, in den Index gelangen, als Duplikat einer anderen Seite gelten, durch noindex ausgeschlossen werden oder nach einer Weiterleitung oder Entfernung verschwinden. Das bloße Hinzufügen einer Adresse zur Sitemap garantiert keine Indexierung. Umgekehrt bedeutet das Fehlen einer Seite in der Map nicht, dass Google sie nicht über Links, Parameter oder externe Quellen findet.
Warum erzeugt WooCommerce so viele Adressen?
Ein Shop muss dem Kunden Sortieren, Filtern, Suchen und die Auswahl von Varianten ermöglichen. Jede dieser Funktionen kann eine neue URL erzeugen.
Nehmen wir an, der Shop hat die Kategorie /shop/stuehle/. Der Kunde kann die Farbe Schwarz, das Material Samt, den Preis von 300 bis 600, die Sortierung nach den günstigsten zuerst und die Ansicht der zweiten Ergebnisseite einstellen. Je nach den verwendeten Plugins können Adressen entstehen wie:
/shop/stuehle/?filter_farbe=schwarz
/shop/stuehle/?filter_material=samt
/shop/stuehle/?min_price=300&max_price=600
/shop/stuehle/?orderby=price
/shop/stuehle/page/2/
/shop/stuehle/?filter_farbe=schwarz&filter_material=samtBei mehreren Filtern wächst die Zahl der möglichen Kombinationen sehr schnell. Hat ein Shop 10 Farben, 8 Materialien, 20 Marken, 6 Preisbereiche und einige Sortieroptionen, bedeutet das nicht einige Dutzend Adressen — durch das Kombinieren der Werte können Tausende oder Zehntausende Varianten entstehen. Die meisten davon haben für einen Google-Nutzer keinen eigenen Wert: Sie zeigen fast dieselben Produkte in anderer Reihenfolge oder einen sehr engen, zufälligen Satz.
Was sollte im Google-Index bleiben?
Die Startseite sollte indexiert sein und einen Canonical haben, der auf ihre primäre Adresse zeigt. Prüfen Sie, dass keine parallelen Versionen nebeneinander laufen:
http://shop.de/
https://shop.de/
https://www.shop.de/
https://shop.de/index.phpAlle zusätzlichen Varianten sollten zu einer gewählten Version führen.
Hauptproduktkategorien beantworten breite Kaufanfragen (Gesichtscremes, Wohnzimmerkommoden, elektrische Schreibtische, Pendelleuchten, Laufschuhe) und sind üblicherweise die wichtigsten SEO-Seiten eines Shops. Eine gute Kategorie sollte eine konkrete H1, eine stabile Adresse, passende Produkte, logische Unterkategorien, eine Beschreibung, die bei der Auswahl hilft, Verlinkung zu verwandten Gruppen, einen eigenen Title und eine eigene Meta-Description sowie einen Self-Canonical haben (die Seite weist auf sich selbst als primäre Version). Wie man die Struktur plant, vertiefen wir im Ratgeber Kategoriearchitektur in einem WooCommerce-Shop.
Unterkategorien mit eigener Intention sollten im Index bleiben, wenn sie eine reale Produktgruppe beschreiben und eine eigene Suchanfrage beantworten — z. B. Gesichtskosmetik → Gesichtscremes → Cremes für trockene Haut → Cremes mit LSF 50. Mehrere Seiten, die fast dasselbe bedeuten, lohnt es sich dagegen nicht zu indexieren (Cremes für trockene Haut, Cremes für trockenen Teint, stark feuchtigkeitsspendende Cremes, Pflege trockener Haut) — wenn sie ähnliche Produkte enthalten und keine klar unterschiedlichen Ziele haben, ist es besser, sie zu einer stärkeren Seite zusammenzuführen.
Produktseiten sollten indexiert werden, wenn man sie kaufen kann, sie Anfragen zu einem konkreten Modell beantworten, einzigartige Informationen enthalten, einen korrekten Preis und eine korrekte Verfügbarkeit haben, mit den richtigen Kategorien verknüpft sind und kein technisches Duplikat einer anderen Variante sind. Eine Produktseite kann für die Anfrage „Schreibtisch Varius 120 × 65 cm Eiche natur“ ranken, während die Kategorie die breitere Phrase „elektrische Schreibtische“ beantwortet — beide Seiten werden gebraucht, sollten aber nicht um genau dieselbe Intention kämpfen.
Vorübergehend nicht verfügbare Produkte. Ein vorübergehender Lagerengpass ist üblicherweise kein Grund, ein Produkt aus Google zu entfernen. Wenn das Produkt zurückkehren soll, behalten Sie seine Adresse, den 200-Code, die Beschreibung und die Bewertungen; zeigen Sie einen Hinweis auf die Nichtverfügbarkeit, eine Benachrichtigungsmöglichkeit sowie ähnliche Produkte. Die vollständige Aufteilung der Entscheidungen für ein Produkt, das zurückkehrt, einen Nachfolger hat oder dauerhaft eingestellt wurde, finden Sie im Abschnitt „Was tun mit einem aus dem Verkauf genommenen Produkt?“.
Ausgewählte Markenseiten können im Index bleiben, wenn sie eine sinnvolle Anzahl an Produkten enthalten, die Marke gesucht wird, die Seite eine eigene H1 und Beschreibung hat, sich von einer allgemeinen Kategorie unterscheidet und interne Links zu ihr führen (z. B. /marke/bosch/, /marke/cerave/, /marke/nowodvorski/). Ein Markenarchiv mit einem einzigen eingestellten Produkt und ohne eigenen Inhalt bringt üblicherweise keinen Wert.
Kontrollierte Landingpages aus Filtern. Manche Produktmerkmale haben echte Nachfrage: schwarze gepolsterte Stühle, elektrische Schreibtische 120 cm, Retinol-Serum, Matratzen 160 × 200 cm, weiße Kommoden 150 cm. Ein solches Thema kann man als eigene SEO-Seite mit einer stabilen, lesbaren URL, einer eigenen H1, einem einzigartigen Title und einer einzigartigen Description, passenden Produkten, unterstützendem Inhalt, einem Self-Canonical, Links aus Kategorien/Menü/Ratgebern und einem Platz in der Sitemap aufbauen. Dieser Artikel beantwortet die Frage, ob ein bestimmter Typ von Filterseite indexiert werden sollte. Die vollständige Logik zur Auswahl wertvoller Kombinationen, zur Kontrolle von Facetten und zur technischen Konfiguration der Filter finden Sie im Ratgeber facettierte Navigation und WooCommerce-Filter — SEO ohne Duplikate.
Blogbeiträge und Ratgeber können informativen Traffic gewinnen und Kategorien unterstützen — ein Artikel „Wie wählt man eine Matratze?“ führt zur Matratzenkategorie, ein Ratgeber über Vitamin C verlinkt auf Serum und Cremes. Ein Beitrag sollte indexiert werden, wenn er eine konkrete Frage beantwortet, die Kategoriebeschreibung nicht kopiert, nützlichen Inhalt enthält und die richtigen Verkaufsseiten unterstützt.
Vertrauensbildende Informationsseiten — über das Unternehmen, Kontakt, Versand, Rücksendungen, Garantie, Referenzen, stationäre Showrooms, betreute Standorte — können im Index bleiben. Nicht jede davon wird viel Traffic gewinnen, aber sie hilft dem Nutzer und der Suchmaschine, das Unternehmen zu verstehen.
Was sollte üblicherweise außerhalb des Index bleiben?
Der Warenkorb (/warenkorb/, /cart/, ?add-to-cart=123) ist eine operative Seite — sein Inhalt hängt vom konkreten Nutzer ab und sollte nicht in den Google-Ergebnissen erscheinen. Üblicherweise setzt man noindex ein, schließt ihn aus der Sitemap aus und verlinkt ihn außerhalb von Interface-Elementen nicht aus SEO-Inhalten. Der Parameter ?add-to-cart= sollte nicht als eigene Produktseite behandelt werden.
Der Checkout (/kasse/, /checkout/, /order-pay/) dient dem Abschluss des Kaufs — er ist keine Zielseite für Suchmaschinen-Traffic. Er sollte noindex haben, nicht in der Sitemap stehen und nur im Rahmen des Kaufprozesses erreichbar sein. Blockieren Sie den Checkout nicht so, dass die Zahlungen nicht mehr funktionieren oder Integrationen nicht getestet werden können.
Mein Konto und Login-Seiten (/mein-konto/, /lost-password/, /edit-account/, /orders/) beantworten keine öffentlichen Anfragen, können Inhalte abhängig vom angemeldeten Nutzer anzeigen und sollten nicht im Index sein. Private Daten schützt noindex jedoch nicht — wenn eine Seite Nutzerdaten enthält, muss sie eine korrekte Authentifizierung verlangen. noindex ist nur eine Anweisung für die Suchmaschine, kein Sicherheitsmechanismus.
Die Bestellbestätigung. Die Seite „Danke für Ihren Einkauf“ kann die Bestellnummer, den Zahlungsstatus, eine Zusammenfassung und Anweisungen zum weiteren Vorgehen enthalten — sie sollte außerhalb des Index bleiben. Zusätzlich sollten Sie prüfen, dass der Aufruf einer zufälligen Bestätigungsadresse nicht die Daten eines anderen Kunden preisgibt.
Interne Suchergebnisse (z. B. /?s=stuhl&post_type=product). Die Shop-Suche kann eine Seite für beliebigen eingegebenen Text erzeugen: Tippfehler, Telefonnummern, zufällige Zeichen, Phrasen ohne Bezug zum Angebot oder automatisch von Bots erzeugte Anfragen. Solche Seiten sollten außerhalb des Index bleiben — meist setzt man noindex ein, hält sie aus der Sitemap heraus und begrenzt das Crawling einer großen Zahl von Parametern erst, nachdem man sich vergewissert hat, dass Google die früheren Anweisungen gelesen hat.
Produktsortierung (?orderby=price, ?orderby=price-desc, ?orderby=popularity, ?orderby=rating). Die Änderung der Reihenfolge schafft kein neues Angebot — es ist weiterhin dieselbe Kategorie mit denselben Produkten. Sortieradressen sollten nicht mit der Basiskategorie konkurrieren. Mögliche Lösungen: ein Canonical zur sauberen Kategorieadresse, noindex, wenn die Konfiguration es erfordert, Sortierung ohne Erzeugung indexierbarer Adressen, Begrenzung interner Links, die zu Parametern führen. Setzen Sie nicht automatisch Canonical, noindex und eine robots.txt-Sperre gleichzeitig — ein solcher Satz erschwert die Interpretation der Konfiguration und ihr späteres Testen.
Die meisten Filterkombinationen. In diesem Artikel sind Filter einer von vielen Adresstypen, und uns interessiert vor allem die Entscheidung: index oder noindex. Standardmäßig sollten Filterkombinationen als Werkzeug für den Kunden behandelt werden, nicht als eigene SEO-Landingpages:
?filter_color=black
?filter_color=black&filter_material=velvet
?min_price=273&max_price=418
?filter_brand=x&orderby=priceMeistens gelangen solche Adressen nicht in die Sitemap, erhalten noindex, werden nicht massenhaft mit gewöhnlichen HTML-Links verlinkt, haben ihr Crawling nach der Planung der gesamten Architektur begrenzt und werden durch kontrollierte Landingpages ersetzt, wenn eine Kombination SEO-Potenzial hat. Den detaillierten Weg zur Auswahl von Facetten, zur Bewertung der Nachfrage und zur Umsetzung der Regeln beschreiben wir im Artikel facettierte Navigation und WooCommerce-Filter — SEO ohne Duplikate.
Dünne Produkt-Tags. WooCommerce-Tags entstehen oft ohne Plan (Aktion, Neuheit, empfohlen, Bestseller, 2026, Sommerkollektion, trendig). Wenn jeder Tag sein eigenes Archiv erzeugt, kann ein Shop Hunderte Seiten mit wenigen Produkten und ohne eigenen Wert haben. Behalten Sie einen Tag nur dann im Index, wenn er wie eine vollwertige Seite verwaltet wird: mit eigener Intention, ausreichend Produkten, einzigartigem Inhalt, stabil und mit Links, die zu ihm führen. Andernfalls setzen Sie noindex ein oder verzichten auf das öffentliche Archiv.
Autoren- und Datumsarchive. In einem von einer Person geführten Shop kann das Autorenarchiv genau dieselben Beiträge enthalten wie der Blog. Ein ähnliches Problem betreffen Jahres-, Monats- und Tagesarchive. Wenn sie dem Nutzer nicht helfen und nur die Inhaltsliste verdoppeln, ist es üblicherweise sinnvoll, sie als noindex zu kennzeichnen.
WordPress-Anhangseiten. WordPress kann für jedes Bild oder jede Datei eine eigene Seite erzeugen (z. B. /produktname/produktfoto/). Wenn eine solche Seite nur ein einziges Bild und den Dateinamen enthält, hat sie als eigenes Ergebnis keinen Wert — meist ist es besser, sie zum passenden Produkt oder zur passenden Datei weiterzuleiten oder die Anhangseiten von der Indexierung auszuschließen.
Wunschlisten und Vergleichswerkzeuge (/wishlist/, /compare/) sind Nutzerfunktionen, keine SEO-Seite. Sie sollten üblicherweise außerhalb des Index, außerhalb der Sitemap und entsprechend abgesichert sein, falls sie Kontodaten enthalten.
Leere und automatische Archive. Eine Seite ohne Produkte, Inhalt und klares Ziel sollte nicht nur deshalb im Index bleiben, weil WooCommerce sie automatisch erstellt hat. Das betrifft u. a. leere Kategorien, ungenutzte Attribute, alte Kollektionen, Testhersteller und die Kategorie „Nicht kategorisiert“. Klären Sie zuerst, ob die Seite gefüllt wird; falls nicht, entfernen Sie sie, führen Sie sie mit einer anderen zusammen oder setzen Sie den richtigen Antwortcode ein.
Tabelle: was indexieren und was blockieren?
| Seitentyp | Standardentscheidung | Häufigster Mechanismus |
|---|---|---|
| Startseite | Indexieren | Index, Self-Canonical |
| Hauptkategorie | Indexieren | Index, Self-Canonical |
| Wertvolle Unterkategorie | Indexieren | Index, Self-Canonical |
| Verfügbares Produkt | Indexieren | Index, Self-Canonical |
| Vorübergehend nicht verfügbares Produkt | Meist indexieren | 200-Code, aktuelle Verfügbarkeit |
| Entferntes Produkt mit Nachfolger | Alte Seite nicht behalten | 301 zum Pendant |
| Entferntes Produkt ohne Pendant | Entfernen | 404 oder 410 |
| Wertvolle Markenseite | Indexieren | Index, Self-Canonical |
| Leere Markenseite | Nicht indexieren | Noindex oder Entfernung |
| Kontrollierte Filter-Landingpage | Indexieren | Index, eindeutige URL und Inhalt |
| Zufällige Filterkombination | Nicht indexieren | Noindex, Crawl-Management |
| Sortierung | Nicht separat indexieren | Canonical zur Kategorie oder noindex |
| Paginierung | Crawl belassen | Eindeutige URL, meist Self-Canonical |
| Interne Suche | Nicht indexieren | Noindex |
| Warenkorb | Nicht indexieren | Noindex |
| Checkout | Nicht indexieren | Noindex |
| Kundenkonto | Nicht indexieren | Noindex und Authentifizierung |
| Bestellbestätigung | Nicht indexieren | Noindex |
| Produkt-Tag | Meist nicht indexieren | Noindex |
| Autoren- oder Datumsarchiv | Meist nicht indexieren | Noindex |
UTM- und gclid-Parameter | Nicht separat indexieren | Canonical zur sauberen URL |
| Anhangseite | Meist nicht indexieren | Weiterleitung oder noindex |
| AGB und Datenschutzerklärung | Je nach Strategie | Oft noindex, ohne Sitemap |
| Wertvoller Ratgeber | Indexieren | Index, Self-Canonical |
| Staging und Testversion | Nicht öffentlich zugänglich machen | Passwort, Zugangsbeschränkung |
Die Tabelle ist ein Ausgangspunkt. Ein B2B-Shop, ein Marktplatz, ein Konfigurator oder ein Dienst mit Tausenden Varianten kann eine andere Politik erfordern.
Paginierung — blockieren oder belassen?
Die Paginierung sollte nicht automatisch blockiert werden, weil sie der einzige Weg von Google zu Produkten auf den späteren Seiten einer Kategorie sein kann (z. B. /stuehle/page/2/, /stuehle/page/3/).
Eine gute Lösung sollte eine eigene URL für jede Seite, gewöhnliche HTML-Links zu den nächsten Seiten, einen Self-Canonical auf jeder Seite, die Möglichkeit für den Robot, zu den Produkten zu gelangen, und keinen Canonical aller Seiten auf die erste Seite gewährleisten. Die zweite Seite zeigt andere Produkte als die erste — sie ist also kein vollständiges Duplikat. Sie muss jedoch nicht in der Sitemap stehen; die Sitemap sollte vor allem die Hauptkategorie und die Produktseiten enthalten.
Infinite Scroll und der Button „Mehr laden“. Der Googlebot verhält sich nicht genau wie ein Kunde — man sollte nicht annehmen, dass er einen Button klickt und automatisch weitere Produkte lädt. Wenn Sie unendliches Scrollen, einen „Mehr anzeigen“-Button oder dynamisches AJAX-Laden nutzen, sorgen Sie dafür, dass die Produkte auch unter gewöhnlichen Paginierungsadressen verfügbar sind, die mit <a href>-Links verbunden sind. Andernfalls sieht Google möglicherweise nur den ersten Teil der Kategorie.
Produktvarianten — eine Seite oder eigene Adressen?
Die Entscheidung hängt davon ab, ob die Varianten eigene Suchanfragen beantworten und ob sie wirklich unterschiedliche Angebote sind.
Eine URL für Varianten bewährt sich meist, wenn sich ein Produkt nur in der Größe, einer einfachen Farbe, einem kleinen Parameter oder der Stückzahl in der Packung unterscheidet (z. B. /basic-shirt/, wo der Kunde Farbe und Größe wählt). Vorteile: eine starke Seite, gemeinsame Bewertungen, weniger Duplikate, einfachere Verwaltung.
Eigene URLs für Varianten können sinnvoll sein, wenn jede Variante eine eigene Nachfrage, eigene Fotos, eine wesentlich andere Spezifikation, eine eigene SKU und einen eigenen Bestand hat, eine eigenständige Zielseite sein kann und in Anzeigen und im Feed als eigenes Angebot präsentiert wird (z. B. ein Telefon mit 256 GB und 512 GB, eine Matratze 160 × 200 cm und 180 × 200 cm). Eigene Seiten sollten stabile Adressen, eindeutigen Inhalt, korrekte Canonicals, konsistente Produktdaten und eine durchdachte Verlinkung zwischen den Varianten haben. Indexieren Sie nicht 40 Varianten separat, wenn jede dieselbe Beschreibung zeigt und sich nur durch ein Wort im Namen unterscheidet.
Was tun mit einem aus dem Verkauf genommenen Produkt?
Verwenden Sie noindex nicht als universelle Antwort auf jedes nicht verfügbare oder entfernte Produkt.
Das Produkt kehrt in den Verkauf zurück: behalten Sie dieselbe Adresse, einen 200-Code, die Beschreibung, die Bewertungen, ähnliche Produkte und eine Benachrichtigungsmöglichkeit. Entfernen Sie das Produkt nicht bei jeder kurzen Bestandsänderung aus dem Index.
Es gibt eine neue Version des Produkts: setzen Sie eine 301-Weiterleitung auf den direkten Nachfolger (z. B. /modell-x-2024/ → /modell-x-2026/).
Kein Nachfolger, aber es gibt eine sinnvolle Kategorie: Sie können zur Kategorie weiterleiten, wenn sie dem Kunden tatsächlich hilft, sehr ähnliche Produkte zu finden. Tun Sie das nicht automatisch für den gesamten Katalog.
Es gibt kein Pendant: belassen Sie einen korrekten 404- oder 410-Fehler. Leiten Sie nicht jedes entfernte Produkt auf die Startseite weiter. Die detaillierten Regeln beschreiben wir im Ratgeber 301-Weiterleitungen und 404-Fehler in einem WooCommerce-Shop.
Noindex, Canonical, robots.txt, 301 oder 404?
Jeder Mechanismus löst ein anderes Problem.
noindex sagt der Suchmaschine: „Du darfst diese Seite besuchen, aber zeige sie nicht in den Ergebnissen.“
<meta name="robots" content="noindex, follow">Verwenden Sie es u. a. für den Warenkorb, den Checkout, Suchergebnisse, das Konto, zufällige Archive und technische Filterergebnisse. Damit Google noindex sieht, muss es die Seite besuchen können.
Der Canonical weist die bevorzugte Adresse unter mehreren identischen oder sehr ähnlichen Versionen aus.
<link rel="canonical" href="https://shop.de/stuehle/">Er kann nützlich sein für Sortierung, Tracking-Parameter, technische URL-Varianten und Duplikate derselben Seite. Der Canonical ist ein Hinweis, kein absoluter Befehl — Google kann eine andere Adresse wählen, wenn die übrigen Signale widersprüchlich sind. Deshalb sollten Canonical, interne Links, Sitemap, Weiterleitungen, HTTPS-Version, Hreflang und strukturierte Daten konsistent sein.
robots.txt legt fest, welche Adressen der Robot nicht herunterladen soll. Es kann das Verschwenden von Ressourcen auf unendliche Parameterkombinationen, technische Endpunkte und unnötige Backend-Pfade begrenzen. Es garantiert jedoch nicht die Entfernung einer Adresse aus den Ergebnissen — Google kann eine URL aus Links kennen und ohne Beschreibung anzeigen, obwohl es den Inhalt nicht heruntergeladen hat. Verwenden Sie robots.txt nicht als Ersatz für noindex.
Die 301-Weiterleitung bedeutet das dauerhafte Verschieben einer Seite. Verwenden Sie sie, wenn sich ein Slug geändert hat, zwei Kategorien zusammengeführt wurden, ein Produkt ein neues Pendant hat, sich die Adressstruktur geändert hat oder eine Seite verschoben wurde. Das Weiterleitungsziel muss thematisch ähnlich sein.
404 und 410. Der Code 404 bedeutet, dass die Seite nicht gefunden wurde; der Code 410 sagt, dass sie dauerhaft entfernt wurde. Sie sind korrekt, wenn kein Nachfolger existiert, die Adresse durch einen Fehler entstanden ist, die Seite keinen Wert hat oder kein sinnvolles Weiterleitungsziel besteht. Ein einzelner 404 ist keine SEO-Katastrophe — das Problem sind tote interne Links, der Verlust wertvoller Adressen und eine große Zahl von Fehlern, die aus einer unkontrollierten Strukturänderung resultiert.
noindex und robots.txt schützen keine privaten Inhalte
Kundendaten, B2B-Dokumente und Partnerpanels sichert man nicht über robots.txt oder noindex — sie erfordern Login, entsprechende Berechtigungen und einen serverseitigen Schutz. Tags für die Suchmaschine sind Sichtbarkeitsanweisungen, kein Zugriffskontrollmechanismus.
Warum lohnt es sich nicht, alle Mechanismen gleichzeitig einzusetzen?
Das Problem ist nicht die Anzahl der Einstellungen, sondern das Senden widersprüchlicher Signale. Beispiel einer schlechten Konfiguration: Eine Seite hat noindex, der Canonical weist auf die Kategorie, die Adresse ist in der robots.txt blockiert und steht gleichzeitig in der Sitemap. Google erhält dann auf einmal die Informationen: nicht indexieren, als Duplikat behandeln, nicht besuchen sowie „die Adresse ist wichtig genug, um in die Map aufgenommen zu werden“. Wählen Sie stattdessen die Lösung, die dem Hauptproblem entspricht:
| Problem | Die richtige Frage | Typische Lösung |
|---|---|---|
| Die Seite soll nicht bei Google erscheinen | Soll sie für den Kunden weiter funktionieren? | noindex |
| Die Seite ist ein Duplikat | Welche URL soll die Haupt-URL sein? | Canonical |
| Die Seite wurde verschoben | Was ist ihr Nachfolger? | 301 |
| Die Seite wurde entfernt | Gibt es ein sinnvolles Pendant? | 404, 410 oder 301 |
| Der Robot verschwendet Zeit mit unendlichen Parametern | Muss die Adresse gecrawlt werden? | Link-Management und robots.txt |
| Der Inhalt ist privat | Wer darf ihn sehen? | Login und Berechtigungen |
Wie sollte die XML-Sitemap aussehen?
Die Sitemap sollte die Adressen enthalten, die Sie indexieren möchten, und nicht eine vollständige Liste von allem, was technisch existiert.
In die Map gehören die Startseite, indexierbare Kategorien und Unterkategorien, Produkte, wertvolle Markenseiten, SEO-Landingpages, Ratgeber sowie wichtige Informationsseiten. Nicht hinein gehören noindex-Adressen, Weiterleitungen, 404- und 410-Fehler, der Warenkorb, der Checkout, das Konto, Suchergebnisse, Sortierung, zufällige Filter, nicht kanonische Duplikate und Entwürfe. Jede Adresse in der Sitemap sollte einen 200-Code zurückgeben, indexierbar sein, einen auf sich selbst zeigenden Canonical haben und den richtigen Inhalt präsentieren.
Bei einem größeren Shop lohnt es sich, die Maps in Produkte, Kategorien, Beiträge, Seiten sowie Marken oder andere kontrollierte Taxonomien aufzuteilen — das erleichtert die Feststellung, welchen Seitentyp Google nicht korrekt indexiert.
Der Parameter lastmod. Das Datum der letzten Änderung sollte sich nach einer bedeutenden Aktualisierung der Seite ändern (Änderung der Beschreibung, Hinzufügen wichtiger Parameter, Aktualisierung des Angebots, Umbau des Inhalts). Es sollte sich nicht bei jedem Nutzerbesuch oder bei einer kleinen technischen Änderung ohne Bezug zum Inhalt aktualisieren.
Interne Verlinkung und Indexierung
Google erkennt wichtige Seiten leichter, wenn gewöhnliche und logische Links zu ihnen führen.
Die wichtigsten Kategorien sollten über das Menü, die Startseite, übergeordnete Kategorien, Breadcrumbs, Ratgeber und Abschnitte verwandter Kategorien erreichbar sein. Produkte sollten Links aus Kategorien, internen Ergebnissen, Empfehlungen, Artikeln und Bestseller-Listen erhalten. Wenn ein Produkt nur auf der 15. Paginierungsseite liegt und nirgends sonst verlinkt ist, wird es möglicherweise seltener besucht.
Verwaiste Seiten. Eine verwaiste Seite hat eine korrekte URL und kann in der Sitemap stehen, aber kein interner Link führt zu ihr. Google kann sie finden, doch die Struktur des Shops zeigt nicht, dass sie wichtig ist. Typische verwaiste Seiten sind alte Produkte, nicht verlinkte Kategorien, Kampagnen-Landingpages, Beiträge nach einer Menüänderung und durch Import erstellte Markenseiten. Die Sitemap ersetzt keine gute Navigation.
Wie prüft man die Indexierung eines Shops in der Google Search Console?
Der Bericht „Seitenindexierung“ zeigt indexierte, ausgeschlossene, blockierte, weitergeleitete, nicht gefundene und als Duplikat gewertete Adressen. Nicht jeder Eintrag im Abschnitt „Nicht indexiert“ ist ein Fehler — wenn dort der Warenkorb, Filter, Weiterleitungen und noindex-Tags stehen, kann der Bericht bestätigen, dass die Konfiguration korrekt funktioniert. Das Problem beginnt, wenn Google eine Hauptkategorie, ein wichtiges Produkt, eine Markenseite oder einen verkaufsfördernden Ratgeber ausschließt.
„Gefunden – zurzeit nicht indexiert“. Google kennt die Adresse, hat sie aber noch nicht besucht oder nicht als wichtig genug erachtet. Mögliche Ursachen: schwache Verlinkung, eine große Zahl unnötiger URLs, eine neue Seite, niedrige Priorität in der Architektur, Serverprobleme, ein überlasteter Shop.
„Gecrawlt – zurzeit nicht indexiert“. Google hat die Seite besucht, aber nicht in den Index aufgenommen. Mögliche Ursachen: dünner Inhalt, Ähnlichkeit zu anderen Seiten, eine leere Kategorie, wenige Produkte, kein Wert gegenüber einer bereits indexierten Seite, ein Soft 404, niedrige technische oder inhaltliche Qualität. Lösen Sie das nicht durch wiederholtes Klicken auf „Indexierung beantragen“ — verbessern Sie zuerst die Seite selbst und ihren Platz in der Struktur.
„Duplikat – Google hat eine andere Seite als kanonisch ausgewählt“. Google hat entschieden, dass eine andere Adresse diesen Inhalt besser repräsentiert. Prüfen Sie den Canonical, die Sitemap, die interne Verlinkung, die Weiterleitungen, die Parameterversionen, HTTP und HTTPS sowie www und ohne www.
„Alternative Seite mit richtigem kanonischen Tag“. Das kann ein korrekter Zustand sein, wenn die Adresse ein technisches Duplikat ist und auf die richtige Version verweist. Versuchen Sie nicht, jede im Bericht sichtbare URL zu indexieren.
„Durch noindex-Tag ausgeschlossen“. Das ist ein korrektes Ergebnis für den Warenkorb und den Checkout. Es ist ein Problem, wenn es eine Seite betrifft, die Traffic gewinnen soll.
„Durch robots.txt blockiert“. Prüfen Sie, ob die Sperre beabsichtigt war. Wenn die Adresse gleichzeitig noindex hat, kann Google diese Anweisung möglicherweise nicht lesen.
„Soft 404“. Die Seite gibt technisch einen 200-Code zurück, sieht aber entfernt oder leer aus (eine Kategorie ohne Produkte, ein Produkt mit der Meldung „nicht gefunden“, eine leere Ergebnisseite, ein Filter ohne verfügbare Produkte). Eine solche Seite sollte gefüllt, weitergeleitet werden oder den richtigen Fehlercode zurückgeben.
Zeigt der Befehl site: die Anzahl der Seiten im Index?
Der Befehl site:ihrshop.de ist für eine schnelle Vorschau nützlich. Sie können prüfen, ob der Warenkorb, das Konto, Filter, Sortierungen, alte Subdomains, Testversionen oder veraltete Produkte erscheinen. Behandeln Sie die Anzahl der Ergebnisse jedoch nicht als exakten Indexierungsbericht — verwenden Sie für die Analyse vor allem den Seitenbericht in der Search Console, die URL-Prüfung, die Sitemap, einen Shop-Crawl und die Serverlogs.
Wie plant man eine Indexierungspolitik Schritt für Schritt?
Schritt 1. Sammeln Sie alle Adresstypen. Beschränken Sie sich nicht auf Adressen aus der Sitemap — sammeln Sie URLs aus einem Crawl, der Search Console, Google Analytics, der Sitemap, den Serverlogs, externen Links, von Filtern generierten Parametern und dem WooCommerce-Panel.
Schritt 2. Gruppieren Sie die Adressen: Produkte, Kategorien, Marken, Filter, Sortierungen, Paginierung, Suche, Tags, Warenkorb und Checkout, Blog, Rechtsseiten, alte URLs, Anhänge.
Schritt 3. Bestimmen Sie die Rolle jeder Gruppe. Fragen Sie für jeden Typ: Könnte ein Nutzer direkt aus Google hierher gelangen wollen, hat die Seite eine eigene Intention, unterscheidet sich der Inhalt von anderen Adressen, ist die Seite stabil, hat sie ein ausreichendes Angebot, lässt sie sich sinnvoll verlinken und sollte sie in der Sitemap stehen.
Schritt 4. Wählen Sie den Mechanismus. Weisen Sie den Adressen zuerst index, noindex, canonical, 301, 404 oder 410, eine Crawl-Begrenzung oder eine Autorisierung zu. Beginnen Sie nicht mit dem zufälligen Hinzufügen von Regeln in der robots.txt.
Schritt 5. Setzen Sie es auf einer Testumgebung um. Prüfen Sie den Code der Seite, die HTTP-Header, den Canonical, den Antwortstatus, die Sitemap, die Links, das Filterverhalten und die mobile Version.
Schritt 6. Führen Sie einen Kontroll-Crawl durch. Der Crawler sollte indexierbare URLs, noindex-Seiten, Canonicals, Weiterleitungen, Fehler, Duplikate, verwaiste Seiten und die Verlinkungstiefe zeigen. Dieser Artikel behandelt die Indexierung im Detail; wenn Sie einen breiteren Überblick über die übrigen Elemente brauchen — Geschwindigkeit, strukturierte Daten, Hreflang, Antwortfehler und technische Konfiguration — nutzen Sie auch die Checkliste für technisches WooCommerce-SEO.
Schritt 7. Überwachen Sie nach der Umsetzung. Beobachten Sie nach der Änderung die Anzahl der indexierten Seiten, die ausgeschlossenen Adressen, den Traffic von Kategorien und Produkten, Serverfehler, die Crawl-Häufigkeit und Googles Auswahl der Canonicals. Bei einem großen Shop müssen die Effekte des Aufräumens der Indexierung nicht sofort erscheinen — Google muss die bestehenden Adressen erneut besuchen und verarbeiten.
Die häufigsten WooCommerce-Indexierungsfehler
Den größten Schaden richten an: eine Sperre in der robots.txt statt noindex, ein versehentliches noindex auf einer Kategorie, die Indexierung aller Filter und ein Paginierungs-Canonical auf die erste Seite.
- 1. Blockieren in der
robots.txtstattnoindexzu verwenden — Google kann die Seite nicht betreten und die Anweisung lesen, sie aus dem Index zu entfernen. - 2.
noindexauf einer wichtigen Kategorie — eine einzige Änderung in den Einstellungen des SEO-Plugins kann eine ganze Produkttaxonomie aus Google entfernen. - 3. Indexierung aller Filter — ein Shop mit ein paar hundert Produkten erzeugt Zehntausende ähnliche Seiten.
- 4. Ein Canonical der gesamten Paginierung auf die erste Seite — Google erhält das Signal, dass die nächsten Seiten Duplikate sind, obwohl sie andere Produkte enthalten.
- 5.
noindexauf einem vorübergehend nicht verfügbaren Produkt — das Produkt kehrt in den Verkauf zurück, wurde aber zuvor aus dem Index entfernt und muss seine Sichtbarkeit erneut aufbauen. - 6. Alle Adressen in der Sitemap — die Map enthält Filter, Weiterleitungen, Fehler und
noindex-Seiten und sendet dadurch widersprüchliche Signale. - 7. Änderung der Adressen ohne Weiterleitungen — alte Produkte und Kategorien beginnen 404 zurückzugeben, obwohl sie unter neuen URLs existieren.
- 8. Fehlende Konsistenz zwischen Canonical, Sitemap und Links — der Canonical weist auf Adresse A, die Sitemap enthält B, und das Menü führt zu C.
Was können Sie selbst prüfen?
Die meisten Indexierungsprobleme lassen sich ohne spezielle Werkzeuge vorab diagnostizieren.
- Geben Sie
site:ihrshop.deein und prüfen Sie, ob in den Ergebnissen der Warenkorb, das Konto, Filter oder die Testversion erscheinen. - Öffnen Sie den Quelltext des Warenkorbs und des Checkouts. Prüfen Sie, ob sie
noindexenthalten. - Öffnen Sie eine Kategorie mit dem Parameter
?orderby=priceund prüfen Sie, auf welche Adresse der Canonical weist. - Testen Sie einen einzelnen Filter und eine Kombination mehrerer Filter. Prüfen Sie, ob sie in die Sitemap oder die Google-Ergebnisse gelangen.
- Öffnen Sie die Sitemap und suchen Sie nach
noindex-Seiten, Weiterleitungen, Filtern und Fehlern. - Prüfen Sie, ob die nächsten Paginierungsseiten eigene URLs und gewöhnliche Links haben.
- Verifizieren Sie, ob die Testumgebung ein Passwort verlangt oder serverseitig eingeschränkt ist.
- Halten Sie die Entscheidung index/noindex/canonical/301/404 für jeden Adresstyp fest, bevor Sie die Einstellungen ändern.
Wann lohnt es sich, das einem Spezialisten zu übergeben?
Die Hilfe eines Spezialisten ist sinnvoll, wenn die Anzahl der erkannten Adressen die Anzahl der Produkte um ein Vielfaches übersteigt, Google andere Canonicals als der Shop wählt oder wichtige Kategorien nicht in den Index gelangen.
Erwägen Sie Unterstützung, wenn der Shop Tausende Produkte hat, die Anzahl der erkannten Adressen die Anzahl der Produkte und Kategorien um ein Vielfaches übersteigt, Filter unendliche Kombinationen erzeugen, Google andere Canonicals als der Shop wählt, wichtige Kategorien den Status „gecrawlt, aber nicht indexiert“ haben, die Sitemap fehlerhafte Adressen enthält, viele Produkte verwaist sind, die Anzahl der indexierten Seiten nach einer Migration gesunken ist, der Shop mehrere SEO-Plugins verwendet, mehrere Sprachversionen laufen, eine nicht standardmäßige Paginierung oder Infinite Scroll umgesetzt wurde oder die Änderungen programmatisch vorgenommen werden müssen.
Bei einem größeren Shop reicht es nicht, ein einziges Feld „noindex Filter“ anzukreuzen. Man muss die Kategoriestruktur, die Keyword-Daten, Traffic und Umsatz, einen Crawl, die Search Console, die Canonicals, die Sitemap, die Verlinkung und die Googlebot-Logs verbinden. Im Rahmen des technischen SEO lässt sich festlegen, welche Seiten indexiert werden sollen, Regeln für Parameter vorbereiten und der Effekt nach der Umsetzung prüfen. Wenn das Problem auch Inhalte, Kategorien, Kannibalisierung und die Sichtbarkeit des gesamten Shops betrifft, kann ein Shop-SEO-Audit der richtige Ausgangspunkt sein.
Häufig gestellte Fragen
Sollten der Warenkorb und der Checkout indexiert werden?
Nein. Das sind operative Seiten, die vom Warenkorb des konkreten Nutzers abhängen. Sie sollten noindex haben und nicht in der Sitemap stehen.
Sollten alle WooCommerce-Filter blockiert werden?
Nein. Die meisten zufälligen Kombinationen sollten außerhalb des Index bleiben, aber ausgewählte Filter, die echte Anfragen beantworten, können als eigene SEO-Landingpages vorbereitet werden.
Entfernt robots.txt eine Seite aus Google?
Das garantiert es nicht. robots.txt begrenzt das Crawling. Um eine Seite aus den Ergebnissen zu entfernen, sollte Google noindex , eine Weiterleitung oder einen passenden Fehlercode sehen.
Sollten Paginierungsseiten noindex haben?
Das sollte man nicht automatisch tun. Paginierungsseiten helfen Google, zu weiteren Produkten zu gelangen. Sie sollten eindeutige URLs, gewöhnliche Links und meist einen Self-Canonical haben.
Was tun mit einem vorübergehend nicht verfügbaren Produkt?
Belassen Sie die Adresse mit einem 200-Code, behalten Sie die Beschreibung und die Bewertungen und zeigen Sie einen Hinweis auf die Nichtverfügbarkeit. Sie können eine Verfügbarkeitsbenachrichtigung und ähnliche Produkte hinzufügen.
Was tun mit einem dauerhaft eingestellten Produkt?
Wenn es einen direkten Nachfolger hat, setzen Sie eine 301-Weiterleitung. Gibt es kein gutes Pendant, setzen Sie 404 oder 410 ein, statt auf die Startseite weiterzuleiten.
Lohnt es sich, Produkt-Tags zu indexieren?
Meist nicht. Eine Ausnahme sind Tags, die als wertvolle Seiten mit eigener Intention, eigenem Inhalt und einer ausreichenden Anzahl an Produkten geplant sind.
Was sollte in der WooCommerce-Sitemap stehen?
Nur indexierbare, kanonische Adressen, die einen 200-Code zurückgeben: Produkte, Kategorien, wertvolle Marken, Landingpages, Ratgeber und wichtige Informationsseiten.
Drei Adressgruppen, ein Mechanismus pro Problem
Eine gute WooCommerce-Indexierung besteht darin, die Adressen in drei Gruppen aufzuteilen:
- Seiten, die Traffic gewinnen sollen — Kategorien, Produkte, Marken, Landingpages und Ratgeber,
- Seiten, die der Kunde braucht, Google aber nicht — Warenkorb, Konto, Checkout, Suche und technische Filter,
- verschobene oder entfernte Adressen — behandelt durch 301, 404 oder 410.
Anschließend muss man einen Mechanismus anwenden, der dem konkreten Problem entspricht, und die Konsistenz zwischen dem Code der Seite, der Sitemap, den Canonicals und der internen Verlinkung wahren.
Wenn Sie prüfen möchten, ob Google die richtigen Teile Ihres Shops indexiert, können wir die Kategorien, Produkte, Filter, Canonicals, die Sitemap und die Search-Console-Berichte analysieren. Im Rahmen des technischen WooCommerce-SEO erstellen wir eine Entscheidungs-Map und nennen konkrete Regeln zur Umsetzung — ohne Seiten zu blockieren, die für den Verkauf arbeiten sollten.